训练AI玩游戏(1)
2013年,那是一个春天,有一个名不见经传的小公司发表了一篇论文Playing Atari with Deep Reinforcement Learning. 这篇文章主要讲述了他们只用屏幕图像作为输入, 用完全同样的算法训练AI玩了7中不同的Atari游戏的故事. 结果相当不错: AI在其中3种游戏中的表现都超过了人类的水平. 不久之后, 这家公司就被Google收购, 它就是现在大名鼎鼎的Deepmind, 后来做出了AlphaGo的公司.
这篇blog的主题是训练AI玩游戏, 主要是讲电脑游戏而不是围棋; 不过既然AlphaGo比较有名,就插几句题外话。AlphaGo也用了Reinforcement Learning的方法,但是它的方法 并不适用于多数电脑游戏。可能有些人知道Deepmind, Facebook等一些公司目前在研究星际争霸这个游戏,那么你觉得围棋和星际争霸对于AI来说,哪个更难呢?
如果你觉得围棋更难,请你再想想。
答案是星际争霸更难,而且是难太多了。至于原因,其实有很多点,我稍微列举一下:
- 围棋有理论最优解。理论上一出生,胜负就决定了。可是星际,根本没有最优解。你的打法是否奏效,取决于别人怎么打。
- 搜索空间的差距。围棋虽然搜索空间很大,不可能穷举。但是围棋的搜索空间跟星际比起来。。。简直就是苍茫宇宙里的一颗原子。围棋只需要300多步就可以下完一盘,所以能用monte carlo tree search + self play 这样的方法。而星际就很难了,因为星际理论上可以无限play下去都不结束,而且真的有很多比赛能打成平局,最要命的是你还很难判断什么是平局。也许你能强行截断1个小时的比赛,但是1个小时能玩多少个step的游戏?职业星际 选手400的apm,一小时能操作24000次。如果用围棋的方法,一辈子也训练不出来。
- 围棋是全局视野,你永远知道对手在干嘛。星际是局部视野,你只能考侦察和经验判断。
- 星际有来自东方的神秘力量等不确定因素(好吧这条是我乱说的)
人类喜欢从自己的主观感受去评价一个东西的难易,其实这是很错误的。好多人觉得,连人类都玩不好的围棋都被AI打败了,人类的末日就要来了! 其实完全没有。围棋对于AI来说,比超级马里奥都要简单的多。所以, 围棋大师们,对不起了,你们的游戏实在是太简单了!(对AlphaGo有兴趣的同学,可以看看Deepmind的论文,其实不是很难,像我这样初中数学文化水平的人也能看个七七八八。)
言归正传。既然讲到训练AI玩游戏,这个东西在专业上属于Reinforcement Learning的范畴。Reinforcement Learning是什么呢? 看下面这张图可能会比较清楚(图片来自David Silver的slides):
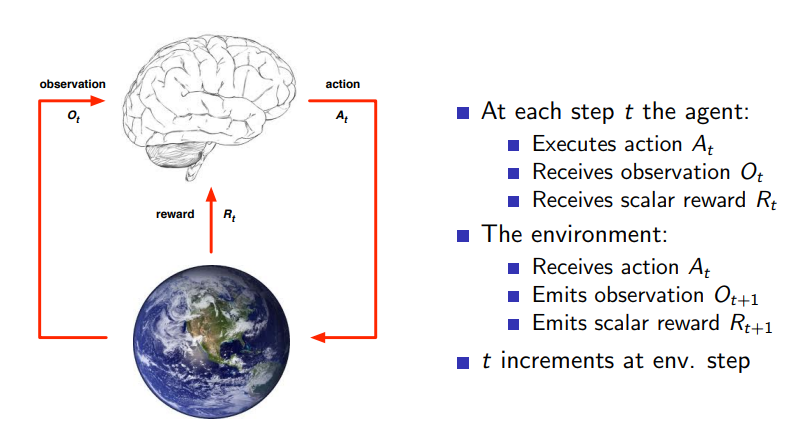
简单的说,Reinforcement Learning研究的问题就是一个Agent, 在一个环境中,根据环境的状态(states/observations)做出action, 并获取reward的过程。
一般讲到Reinforcement Learning, 就要讲Markov Decision Process,讲到Bellman Equation, 然后一大堆公式,但是那样可能比较无趣,所以我决定跳过这个东西,直接讲算法。
Reinforcement Learning的算法有很多,常见的有两类,一类是Policy Based, 一类是Value Based. 所谓Policy Based就是我建立一个模型,它输出一个概率\(P(s, a)\),也就是在某个state下采取某个action的概率。 所谓Value Based就是我建立一个模型,它输出一个value \(V(s, a)\), 也就是在给定state下采取某个action所能得到的总收益。这两种方法并不是互斥的,比如AlphaGo就同时使用了这两种算法。
现在我们来看Deepmind经典的Atari游戏,它用的是一种叫Q Learning的算法。什么是Q learning呢? 其实很好理解,我们有一个Q函数:\(q(s, a)\),它接受两个输入,\(s\)是当前的state,而a是采取的action, q用来model在这个state下采取这个action后所得到的收益。关于收益,我们一般是这么定义的:
\[v = r_{t1} + \gamma \cdot r_{t2} + \gamma ^ 2 \cdot r_{t3} + ...\]其中\(\gamma\)我们叫做decaying factor, 也就是我们认为远期的reward不如近期reward而加上的一个小于1的参数,例如\(\gamma = 0.99\)。我们要设计一个q函数数去最大化我们的收益,所以我们有:
\[q(s, a) = r + \gamma \cdot \max_{a'}{q(s', a')}\]假如我们能够对q建立一张表,然后记录所有的state和action, 然后不停的按上面这个式子进行迭代,问题就转成一个动态规划解决了(base case: 当游戏结束的时候,q=r)。
但是事实没有这么简单。考虑这么一个问题: 我们的游戏里有多少种state? 每个state下有多少种action?
对于atari游戏来说,state是屏幕上像素的所有可能,这是个天文数字。action还好,是手柄上按键的数目(假如不考虑好几个键一起按的情况)。对于星际争霸来说,action space也是个天文数字。所以,q这个函数是 不可能用表格来解决的。那么怎么办呢?这个时候我们就需要建立一个估计函数\(q' \approx q\),然后用真实的reward和action作为输入来训练它。最常见的approximator就是神经网络了,把神经网络引进来估计q, 这个方法 就叫Deep Q Network。
当我们比较准确的估计了q以后,这个问题就很明白了:我只要对一个state输出所有action的q, 然后选取q最大的那个action,就可以达到最优了。
好了,虽然实际应用时有很多的细节,不过Deep Q Network基本的理论也就是这样了。具体的东西等下一篇讲到代码的部分再一起讲。有兴趣的同学也可以先看看代码: https://github.com/codescv/nesgym
一些思考:
- 可以看到q learning对游戏本身的model没有任何假设,这是它最强大的地方,AI不care它在玩的是什么,只要你有reward,它就能训练。
- q learning针对action, state和reward进行训练, 但是这些东西并不需要是agent自己经历的,别人的经验也可以拿来train.
- reward function至关重要。有一个好的reward function就等于成功了一半。这也是为什么atari游戏比较容易训练,因为atari游戏,例如打砖块和打飞机,reward来的非常快。而超级马里奥 则非常难。因为一关很长,只有最后才有reward(当然还有一个问题是超级马里奥没有全局视野,这点我们以后再说)。
- 虽然q learning已经非常general了,但是它离智能其实还很远。原因还是在于reward. AI必须依赖人类给的reward信号才能训练,否则它并不知道赢是好的,输是坏的。而人类却能很自然的知道这一点。 越研究AI,越觉得人类实在是太了不起了。